
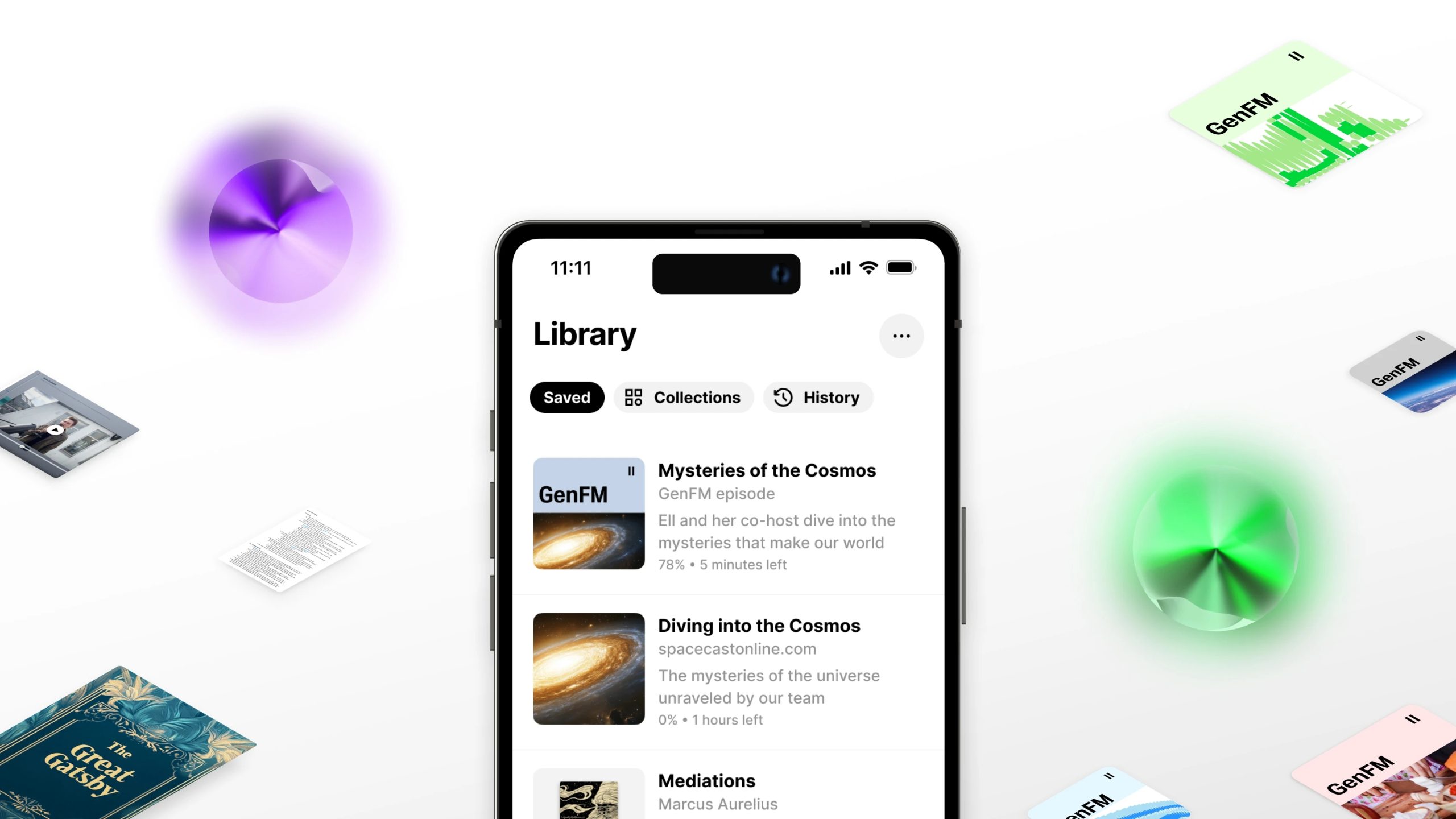
ElevenLabs expands its AI-powered voice technology with the introduction of GenFM, a generative audio model designed specifically for long-form spoken content. This new model, integrated into the ElevenReader platform, offers a significant upgrade in naturalness and engagement for audiobook narration, podcasts, and other extended audio formats.
GenFM leverages advanced deep learning techniques to produce highly expressive and nuanced speech, moving beyond the robotic or monotonous delivery often associated with traditional text-to-speech systems. Its ability to capture subtle variations in tone, pacing, and emphasis results in a more immersive and human-like listening experience.
ElevenReader users now have access to GenFM’s capabilities, allowing them to transform written text into captivating audio content with minimal effort. The platform’s intuitive interface simplifies the creation process, enabling users to easily customize voice parameters and fine-tune the generated audio to their specific needs.
This new model represents a substantial advancement in long-form speech synthesis, addressing the growing demand for high-quality audio content creation tools. GenFM’s superior performance opens up exciting possibilities for authors, podcasters, educators, and anyone seeking to create compelling audio experiences. By integrating cutting-edge AI technology, ElevenLabs continues to empower individuals and businesses with the tools they need to produce professional-grade audio content effortlessly. The availability of GenFM within ElevenReader further solidifies the platform’s position as a leading solution for generating realistic and engaging synthetic speech.
Leave a Reply